The Whats, Whys, and Hows of Reinforcement Learning.
This post is for anyone who wants to understand the three big questions (WWH) of Reinforcement Learning. Whether you are a beginner or a machine learning veteran, chances are that you have heard about Reinforcement learning and you always had this inkling to understand this less known sibling of the popular machine learning paradigms like Supervised and Un-Supervised ML. I will try my best to provide a concise and hopefully interesting answers to these basic questions through this blog post.
Back Story - How do we learn?
From the moment a child is born into this world, it is bombarded with a ton of information through the sense organs like eyes, skin, nose etc and the learning process starts. Our nervous system processes these sensations or stimuli and then controls our physiological system to perform tasks in the real world. During this learning process, we often make mistakes and learn from them. Once we get good at these tasks we usually get a positive reinforcement like applause and appreciation (at times self-appreciation). These implicit/explicit feedbacks help us continuously gauge and improve our performance at any task or challenge.
Let’s take riding a bicycle for example. Just recall the first time you rode a bicycle and the struggle of you trying to balance it. Initially, It would have felt impossible to learn, but eventually, your brain learned to control the posture, pedaling, and movements to effortlessly bike (and now you can flaunt your biking skills). Each time you fell, your brain learned how not to make the same or similar mistake. This happens because our brain maps these sensations a.k.a stimulus to appropriate actions through a trial and error process. Most of us can recall that the frequency of falling from the bike reduced drastically with each trial. As a matter of fact, if we dissect this process or any learning process in general, we would find that there are a couple of essential elements involved. The environment i.e the bike, road (and the world around), the agent i.e you, and a reward or cost signal i.e falling or successful. I would argue that these three are crucial elements in any form of learning. This is also the motivation for Reinforcement Learning.
The What ??
Reinforcement Learning (RL) is one of the major paradigms of machine learning and artificial intelligence. It comprises of methods that can learn behaviors to optimize the performance of an agent (e.g. a robot or an algorithm) at a task by maximizing rewards (or minimizing costs) received from the environment to reach the desired goal. This is unlike other learning paradigms like supervised and unsupervised learning, where learning is dependent on the collected data. These behaviors, also known as policies, are defined by the controls or actions taken by the agent in various situations (system states) of the environment.
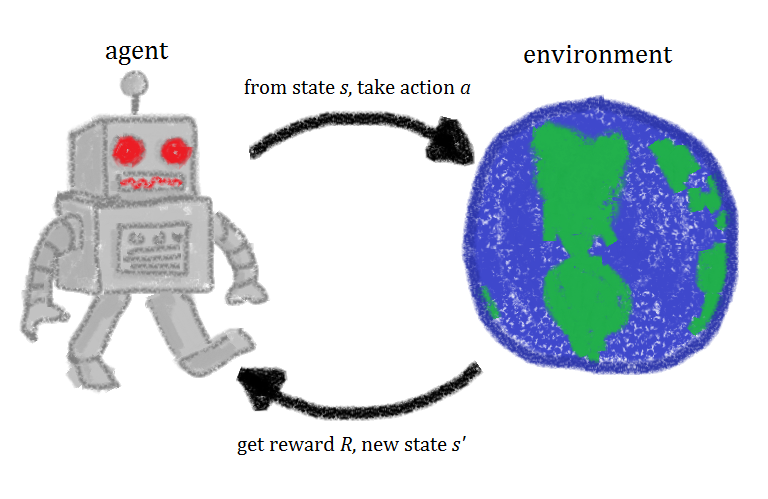
There are primarily two basic elements of Reinforcement Learning namely an agent and an environment. The entire domain of RL works on the interaction between these two elements as we show in the illustration. These basic elements further contain some sub-elements and together they provide a general framework for all reinforcement learning problems.
Environment is defined by a system that contains the basic building blocks of the problem like a state (current situation), an interface for the agent to interact (like using robot arms), the manifestation of the task itself (pick a ball), ability to change its state depending upon the external interactions or internal process. Additionally, it also refers to the world in which our agent resides and defines the boundaries or limits to the execution of actions. Mathematically, it is defined as a set of states that are affected both by some internal known/unknown process and the interactions with the agent. The objective of an agent is to use its controls or actions to reach a desired goal state in the environment.
Agent refers to the actor responsible for solving the problem or achieving the desired objective. It might be a computer, an actuator, a robot, or a virtual game player. An agent is a complex entity that has four important sub-elements namely policy, cost/reward, cost/value function, and optionally a model. We now discuss them in detail.
- Policy refers to the mapping of a state to action or control and this defines the behavior of the agent. Although it is important to note here that the agent doesn't need to know the actual state of the environment, (for example in the partially observable Markov decision process (POMDP), the agents just have a belief state which is a probabilistic estimation of the actual environment state). The agent estimates the state (perfect or probabilistic) of the environment as observation through the sensors and then uses the policy learned through the RL algorithm to reach the goal. It is sufficient to say that the goal of any RL method is to learn an optimal policy.
- Cost/Reward is an important signal required to estimate the quality of the learned policy. Generally, every state transition yields an associated reward or cost (except the final state that has a terminal cost) that is determined by the agent based on some pre-defined metric of the problem statement. For instance, in a search and rescue scenario, the reward could be defined by the proximity to the lost person, whereas in pipeline repair the cost could be defined by the number and the disrepair of damaged sites. It is also important to note that reward and cost are essentially the same signals with their sign reversed i.e. \\(\mathbf{cost = -reward}\\). For the sake of simplicity, we will now use cost in the remaining post. Designing the cost signal, i.e. defining the cost of a state transition is of fundamental importance in formulating an RL problem. It could be easy for some problems, and tricky for others (thinking in terms of the quantity or parameter that needs to be optimized might help).
- Cost/Value Function maps to the overall quality of the state by taking into account the future course of actions and consequently states, that can be reached from the current state through the policy. A state might have a high immediate cost but a low value of cost function suggesting better suitability. The cost (also known as stage cost) helps to gauge the immediate desirability of a state, whereas the cost function is used to determine the long-term desirability. Another noteworthy difference is that cost is a part of RL problem formulation whereas cost function is dependent on the algorithm used to estimate it. It would be an understatement to state that the quality of an RL method depends on the quality of its cost function estimation.
- Model is an important but optional sub-element used for planning, that helps us to predict the state transition of an environment in simulation. While there are some problems where it may not be required, as the agent can learn through multiple trials in the real environment, in most practical applications a model is desired. Most RL problems can be formulated as Markov Decision Processes (MDP), which I will discuss in detail in the next blog.
The agent enters the system and observes the so-called initial state, then uses a policy to reach the desired goal state in the environment. Once the desired state is reached we terminate the execution of the agent and call this an episode.
The Why ??
I feel that this is an important question, considering that there are many learning methods available today. Especially with the tremendous success of supervised and semi-supervised machine learning in the last decade with Deep Neural Networks, fast computing machines, and GPUs, this question has become more relevant. But the answer in my opinion is very straightforward - supervision is costly and unnatural (but still necessary and relevant). Let me elaborate on this using these points.
Annotation is costly Most of the supervised ML algorithms rely on the annotated dataset with explicit supervised target signals. More often than not, these efforts require human expertise, and hence creation of such datasets is costly. Simply put, these algorithms are successful only where there is a straightforward mapping between input and output.
Annotation is unnatural This might be controversial to some, but I also believe that learning the mappings explicitly is also a form of unnatural learning, in the sense that we do not specify the objectives or tasks for such (supervised and unsupervised) algorithms nor do we have some environment to interact with. (one could argue that minimizing loss is an objective). But, I do want to acknowledge that this may be a sufficient form of learning. We do not need to imitate the bird to build a mechanical bird (airplane). Reinforcement learning, on the other hand, is a more natural way of learning i.e. using trial and error in an environment. I think that RL is more closer to the concept of General AI than its supervised counterparts.
Annotation is limited in scope This might be the most controversial of all but I believe that algorithms based on annotated systems cannot reach general AI (even in theory). But they are still necessary and invaluable.
RL is responsive by design i.e. the same algorithm can adapt to new environment and changes in input using the cost signal using the process of failing and learning. For its supervised counterparts, it might require creating a new dataset.
RL is practical in application i.e. we do not need to learn mappings that are statistically rare. If a set of states are very rare, the agent will likely never encounter it and hence it does not need to learn it.
That being said, there are also practical issues with RL like modeling the environment, reset-problem, defining objectives, costs, etc. Again, I do not want to undermine the importance of supervised learning and I believe that success in Supervised methods is crucial to the eventual success of RL and then General AI.
The How ??
Finally, let’s get to the question of how to get started in RL. I created this list of resources to help you learn the basics and get you off the ground.
- Reinforcement Learning: An Introduction
- Reinforcement Learning and Optimal Control
- Algorithms for Reinforcement Learning
- Spinning Up in Deep Reinforcement Learning
P.S. I will also be posting a simple quick start guide to RL in my next post.
This post is derived from my MS thesis at ASU. I would highly appreciate you going through it and providing me a feedback.